右片麻痺のmoorです。
音声起こしという仕事をしています。
自動音声認識
以前の記事で「自動音声認識AI「Whisper」がすごい・音声起こしに使える!」を書きましたが、Googleの開発したGeminiでも文字起こしができるという記事を見つけました。

少し分からない点もあったので、ほかにも2点ほど見つけました。


Whisperも、私には守秘義務が厳密でないものの場合は助かりましたが、より簡単に使えるので、やり方を記録しておこうと思います。
使い方
通常のGeminiのサイトでなくGoogle AI Studioを使用します。無料枠で十分だと思います。

ピンクの矢印のところの「sign in to Google AI Studio」をクリックします。(もしGoogleアカウントがない、もしくは別アカウントで入りたい場合は紐づけてください)
Use Google AI Studioの「Try Gemini」をクリックしたら、注意書き等が出るので、読んで同意します。
これで使う準備はできました。
次に、左の緑矢印のところの「Chat」「Create Prompt」に切り替え、ピンクの矢印のところの「Model」が最新版のGemini(「Gemini 2.5Pro」「Gemini Pro 2.0 Flash」)になっているか確かめる。
※記事を書いて以降、アップデートしたようで精度が上がっています。以前の文章を訂正しています。以下の画像は古いままですが、場所的には一緒です。
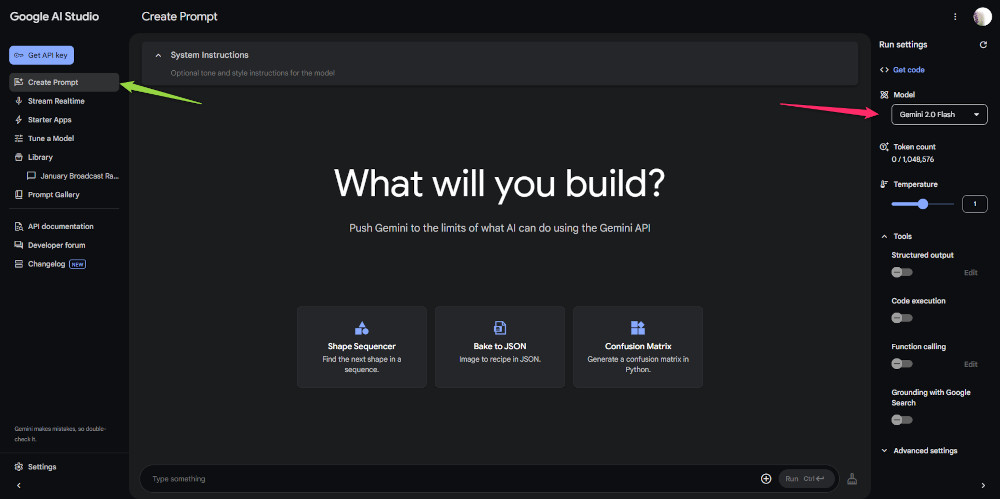
黒画面の場合ちょっと見にくいですが、ピンクで囲っている一番下の部分が入力画面なので、その右側にあるプラスボタン(+)を押します。
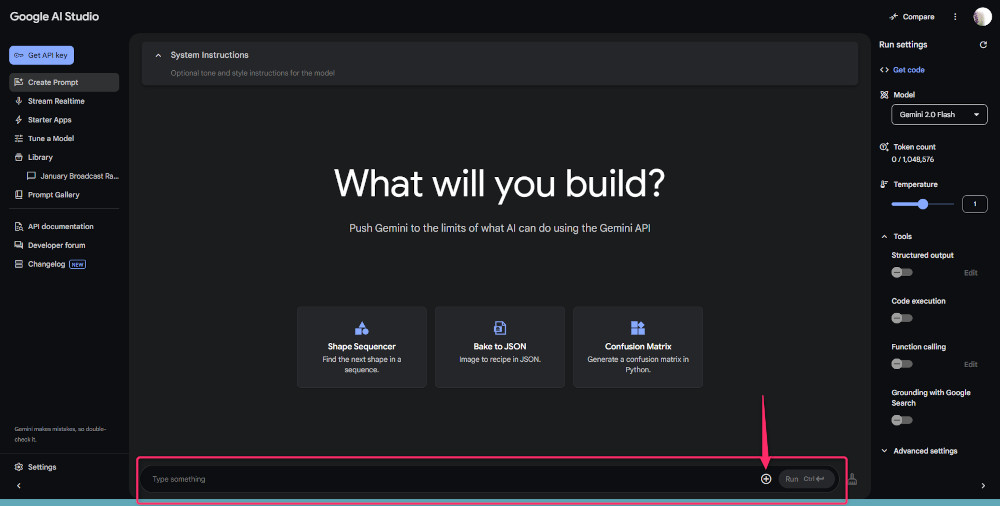
メニューが開くので、一番上の「Allow Drive access」をクリックしてGoogleドライブと接続します。
次に、文字起こししたい音声ファイルを、2番目の「Upload file」をクリックして入れます。
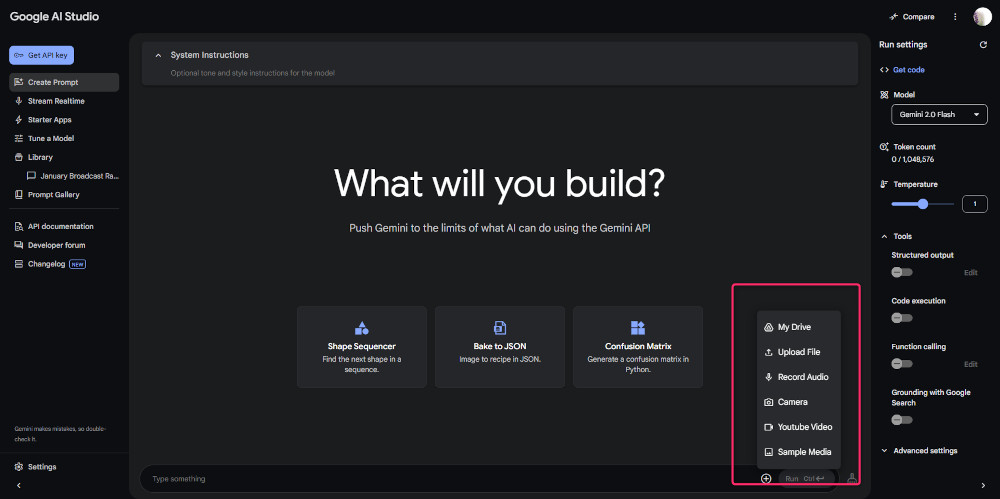
今回は、20250313のニュースを録音したもので試していますが、アップロードできると下に音声が入ります。
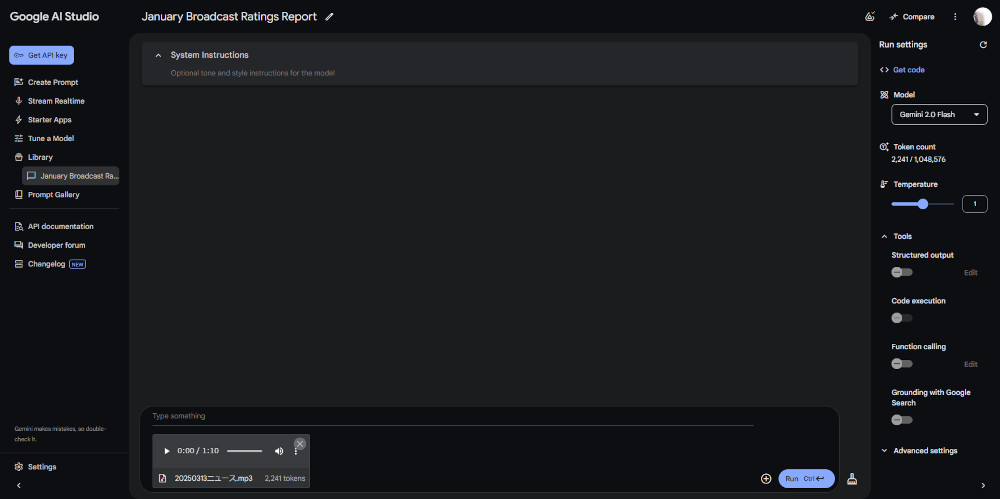
音声の上の「Type Something」と書いたところ(ピンクの矢印のところ)にプロンプト(指示や質問)を入力します。
今回は「会議の音声を、「えー」「あのー」「えっ」「え」などは除去して、全て文字起こししてください。」と入力しました。
そして、右のボタンをクリックすれば開始します。
今回は1分ほどの音声なので、あっという間にできました。
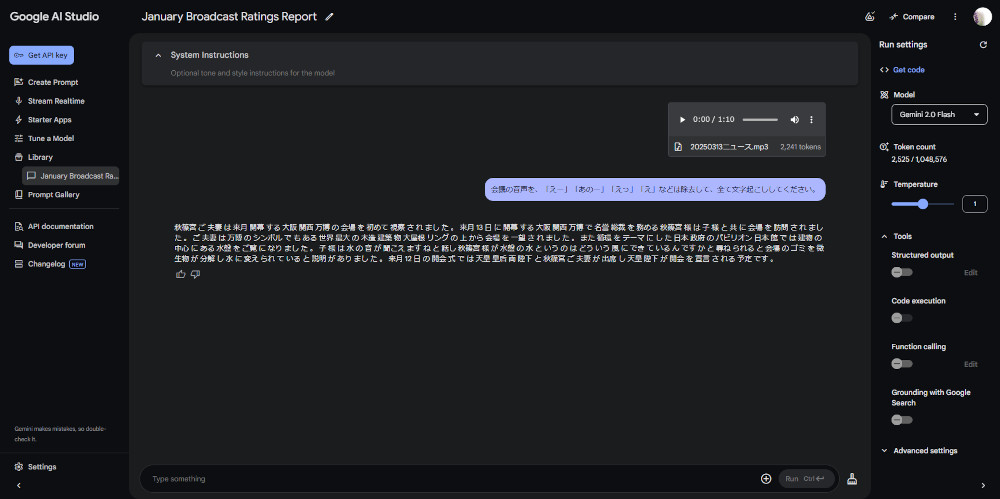
これをコピーしてテキスト(私は「秀丸」というtextソフトを使っています)に貼り出しました。

半角の空白が多数ありましたので取り除く(置換で半角空白をなしにする)と、おおむね起こせています。(「紀子様」が全滅でしたが)
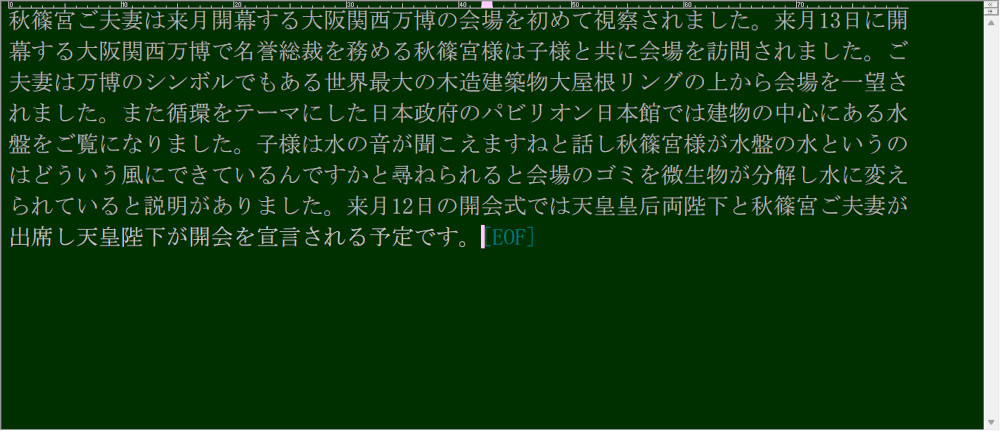
※使った音声
プロンプト(指示や質問)の書き方を工夫すれば、もっと使えそうです。
(このニュースのものでは分かりにくいが、今回のプロンプトは、私の文章が下手で、オノマトペの除去が、あまり機能していなかった)
また
- 「発言者ごとにタイムスタンプと発言者の名前を付けて」等を付け加えて、話者ごとに区切ってタイムスタンプをつける。
- 「口語体から文章体に」等を付け加えて、文章体に変える。
など、いろいろ出来るみたいです。
ただ、長い音声だと、何回か出力が止まり、「続けてください」等と続行の指示をしないと駄目でした。
私は、しばらくはWhisperをメインで使いそうです
割と簡単に使え、精度も、私的には満足で、出力も早かったんですが、私は、しばらくはWhisperをメインで使いそうです。
理由は
- 長い音声だと、出力が止まり、「続けてください」と続行の指示を出さないといけなくて、それが、いつなのかが分からなくて、ずっと見ていないといけないのと、最後まで終わったのが分かりにくい。
- 出力したものに、半角の空白が多数あるので、取り除く作業が邪魔くさかった。(邪魔くさがり(^_^;)
- 話者ごとに区切ってもらう作業や、文章体に直すような作業が、あまり私のやり方では必要ない。
ただ、使い方はWhisperより簡単なので、適材適所で、両方を使うと思います。
しかし、私の仕事も、そう遠くない将来に、なくなりそうな勢いの発展ぶりです(T_T)ww

