右片麻痺のmoorです。
病気前、音声起こしという仕事を家業としていました。
しかし、片手しか動かなくなって、タイピングもゆっくりだし、よく間違うし、もうできないだろうと諦めて、廃業届けを出して主人の扶養家族にしてもらい、店じまいするつもりでした。
しかし、急がないからと声をかけてくださる方がいて、やってみたら何とかできたので、少しずつですが仕事をお請けさせていただいてます。
復帰するときに、今まで使っていたソフトの設定や、やり方を忘れていて難儀したこともあり、私なりのやり方を、記録しておこうと思います。
自動音声認識
最近、AIがどんどん進化して、音声認識を通じてテキストを抽出してくれるサービスが、どんどん出てきました。
守秘義務が厳密でないもののときは、無料・有料のもの含めて、いろいろ試してみています。
先日、すごい記事を見つけました。
この記事だけでは、私には若干理解できなかったので更に調べました。

Whisper
Whisperとは、OpenAIが開発している汎用的な音声認識モデルです。

動かすのにGPU環境でないと厳しく、GPU搭載パソコンでない場合は、Google Colab 無料版GPU環境を用いて行うと無料で使えます。
★できれば、Whisperをパソコン内で動かすことができればと思って、インストールしてみた方を見つけたんですが30分の音声で5時間かかったとのことで実用的じゃなさそうです。

★追記(20260512)
Pythonで入れることができる方法を詳しく書いた方を見つけ、私もパソコン内に入れられたんですが、私が使いたいモデルサイズ「medium」では、5分の音声で1時間待っても、うんともすんとも言わなくて、待ってられずに諦めました。モデルサイズ「base」だと使えますが、精度が私的には不満でした。

追記終わり
使い方
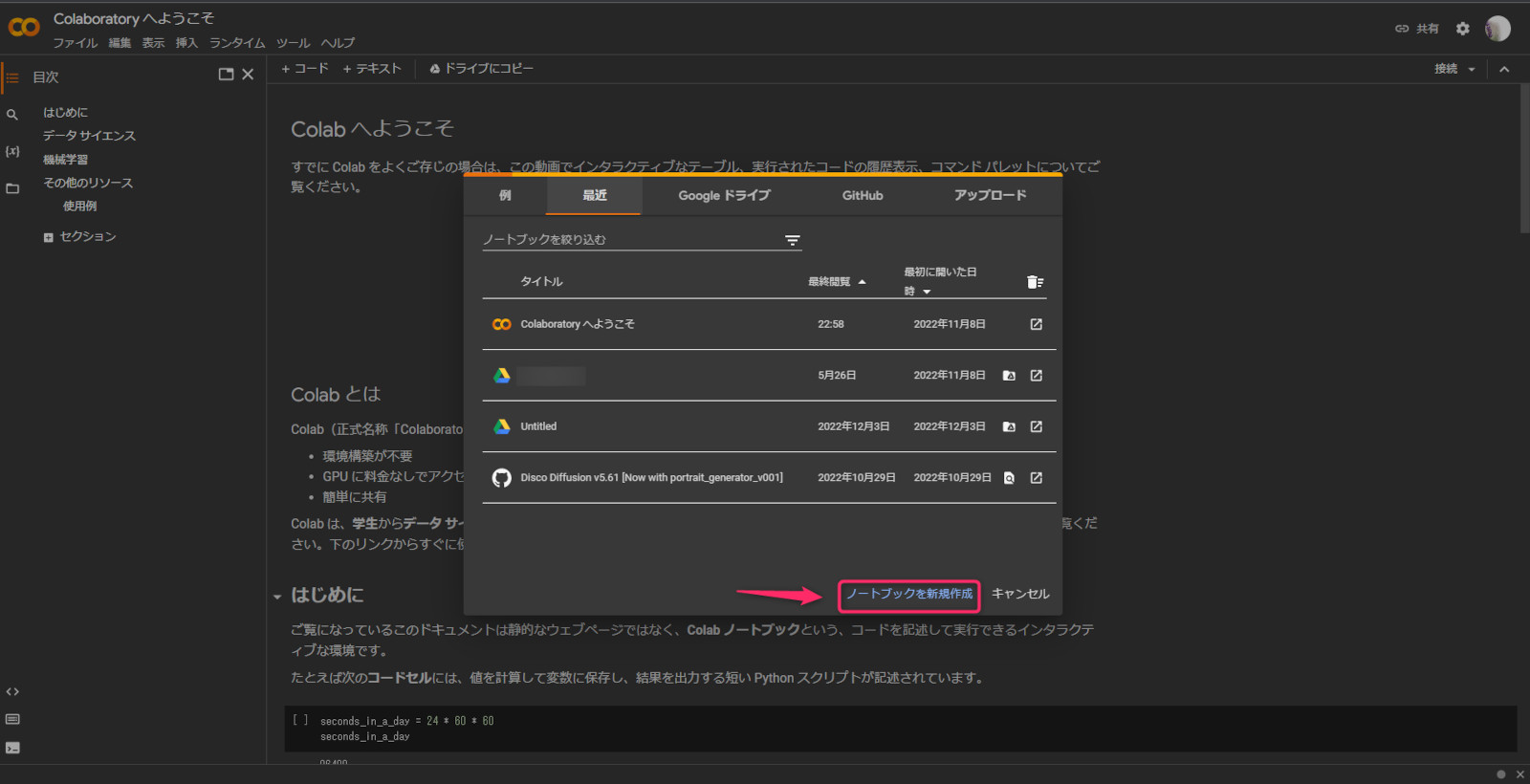
Google Colaboratory のサイトへ行き。

ピンクで囲んだ「新しいノートブックを作成」を選び、作成する。
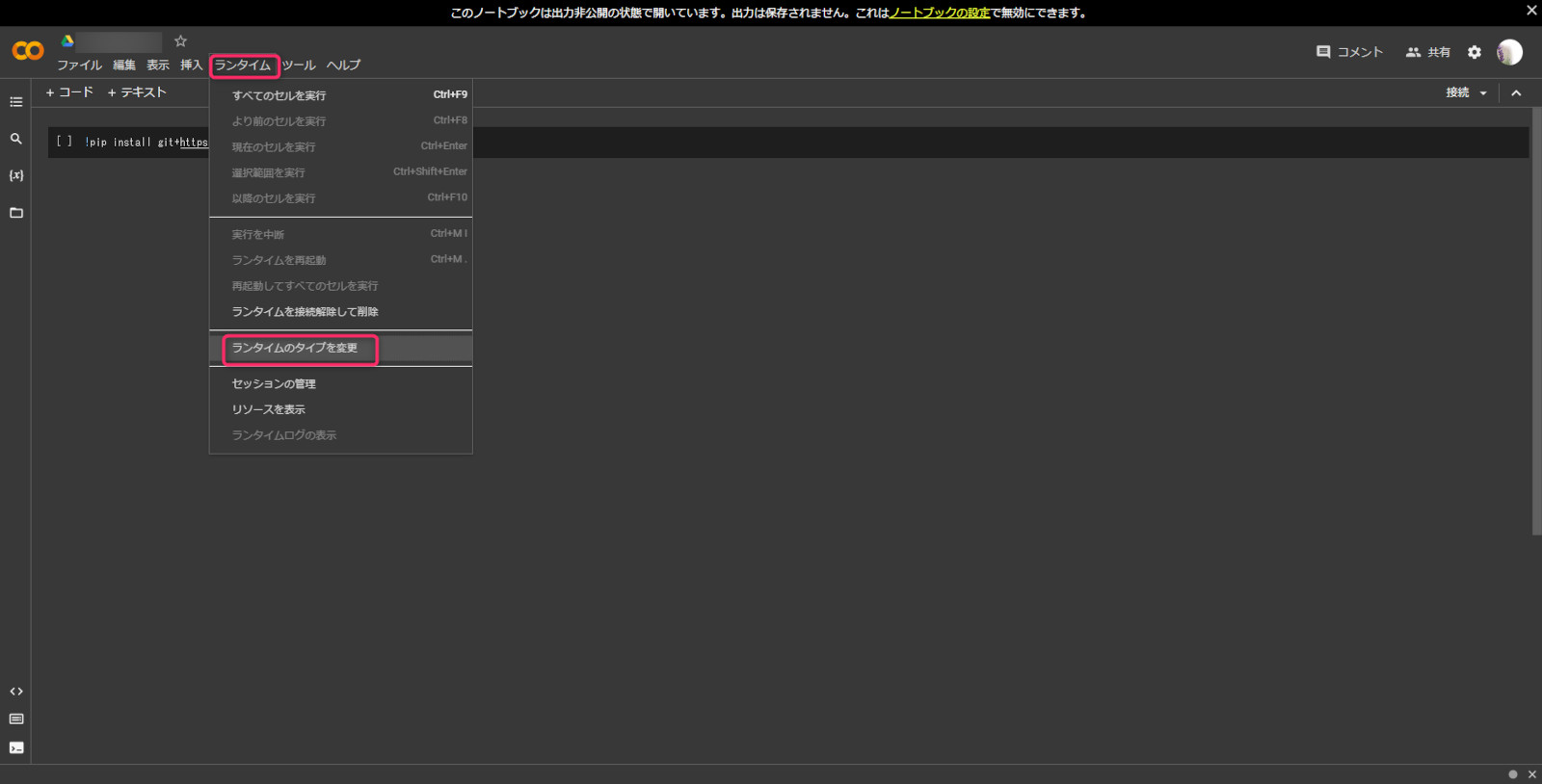
GPU環境にするために「ランタイム」の中からピンクで囲った「ランタイムのタイプを変更」を押す。
そしたら、ノートブックの設定が出るのでハードウェア アクセラレーターから「GPU」を選んで保存する。
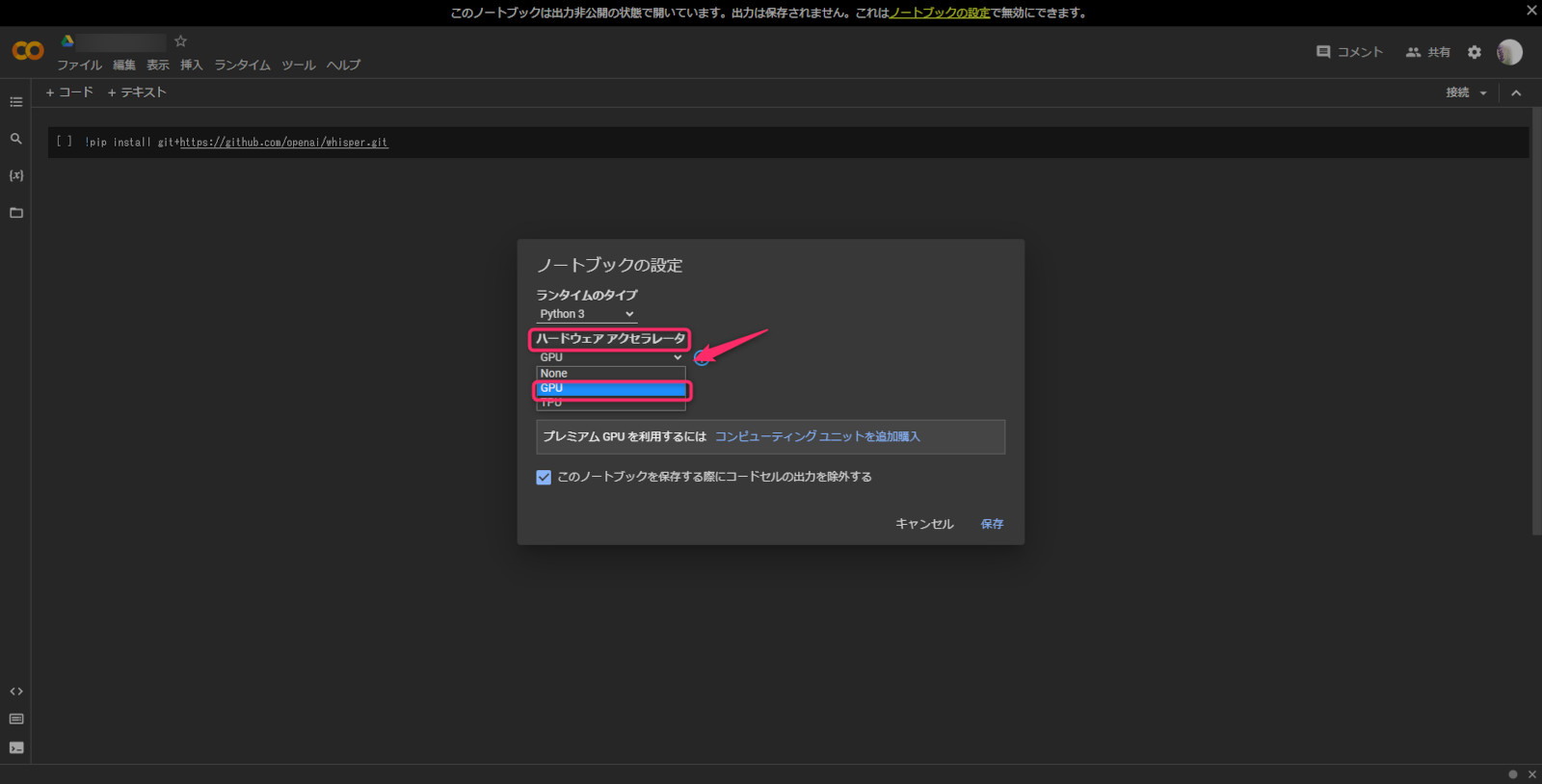
下記コードを入力し、ピンクの矢印のところのマークを押して実行する。
!pip install git+https://github.com/openai/whisper.git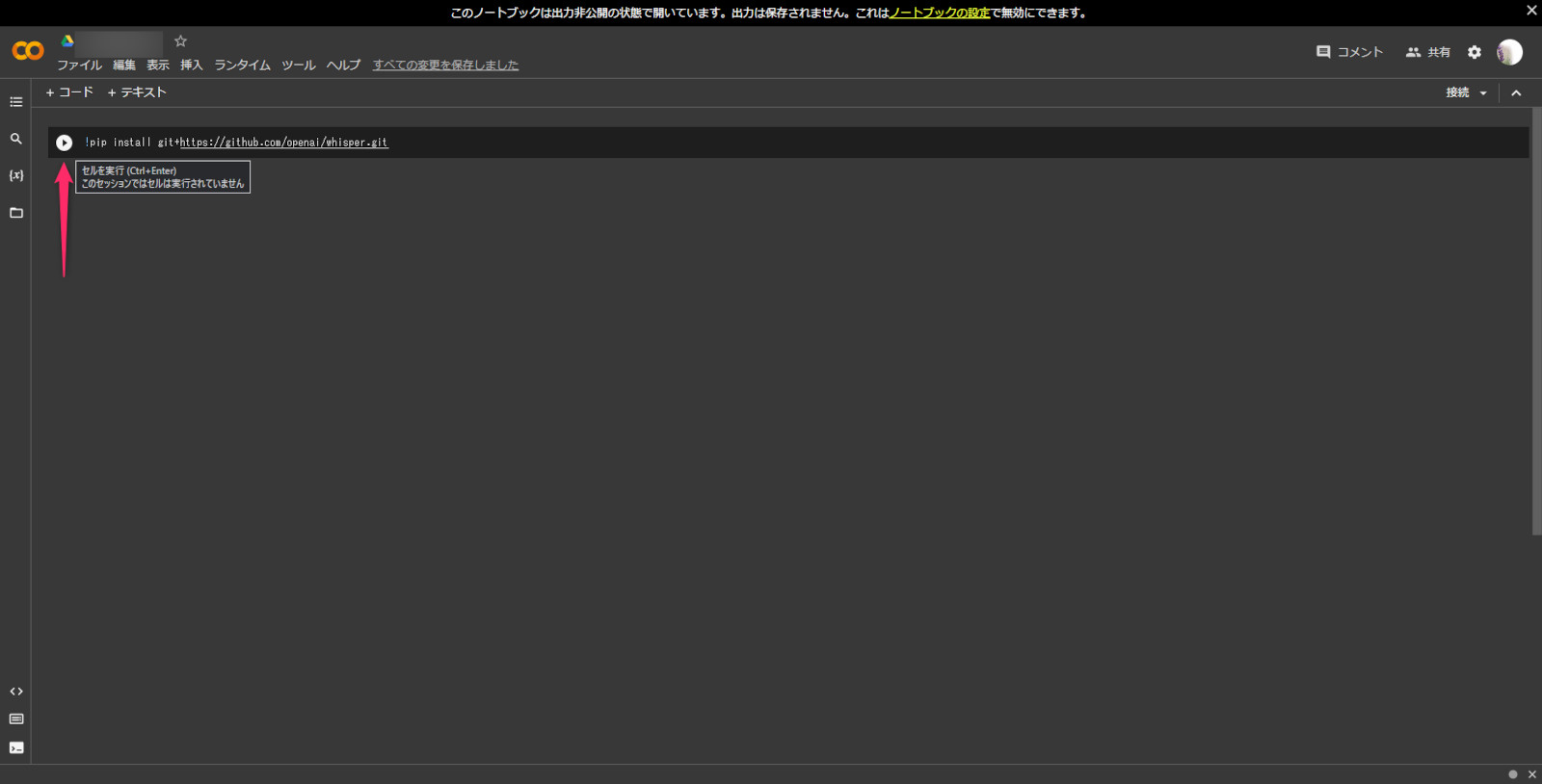
読み込みが終わったら緑の✓が入る。
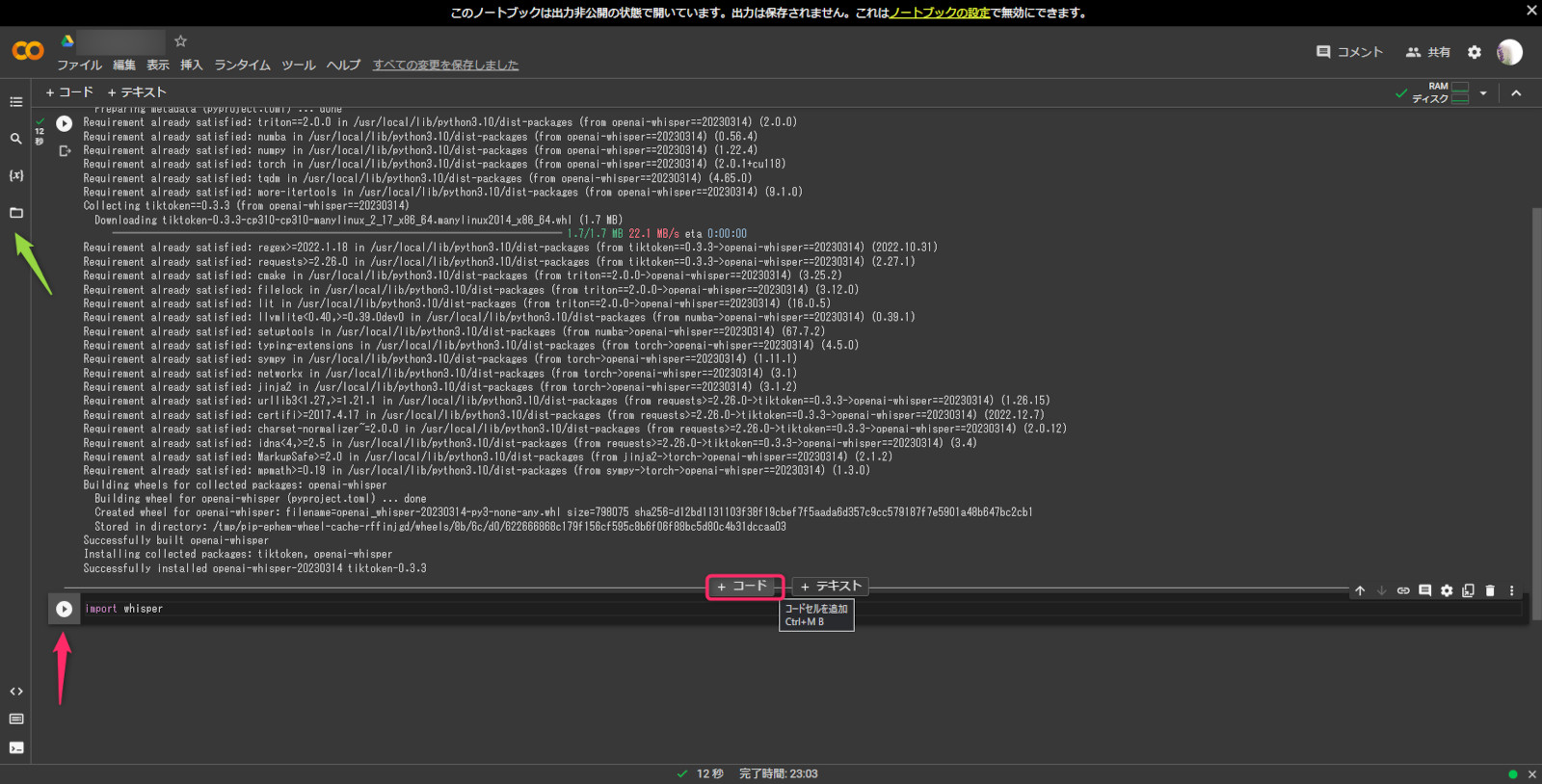
次に、コードを+して、下記コード入力して実行する。
import whisperそして、緑の矢印のファイルの欄を開く。
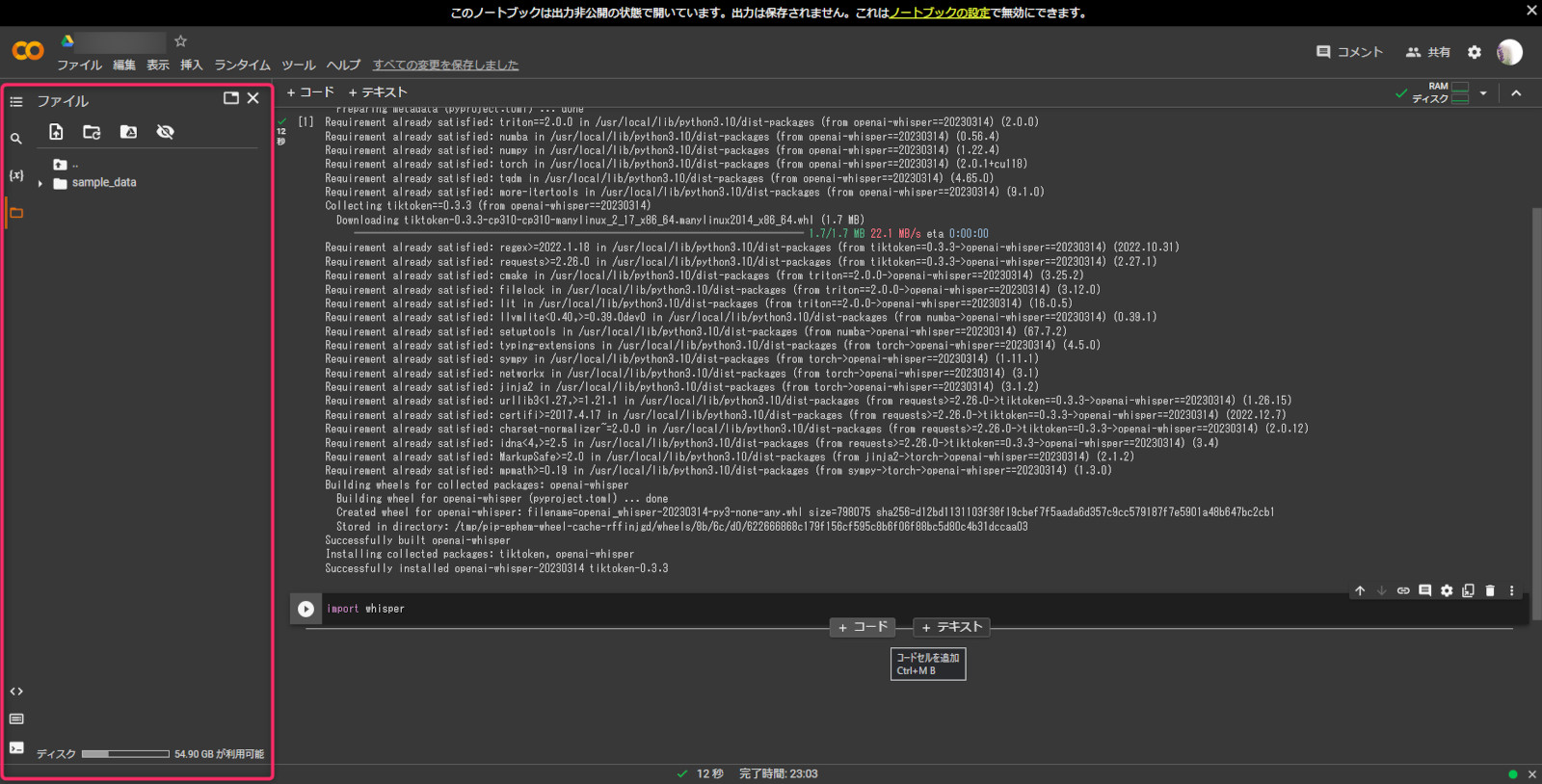
ピンクで囲んだところに読み込みたい音声ファイルをドラッグしたら読み込んでくれる。
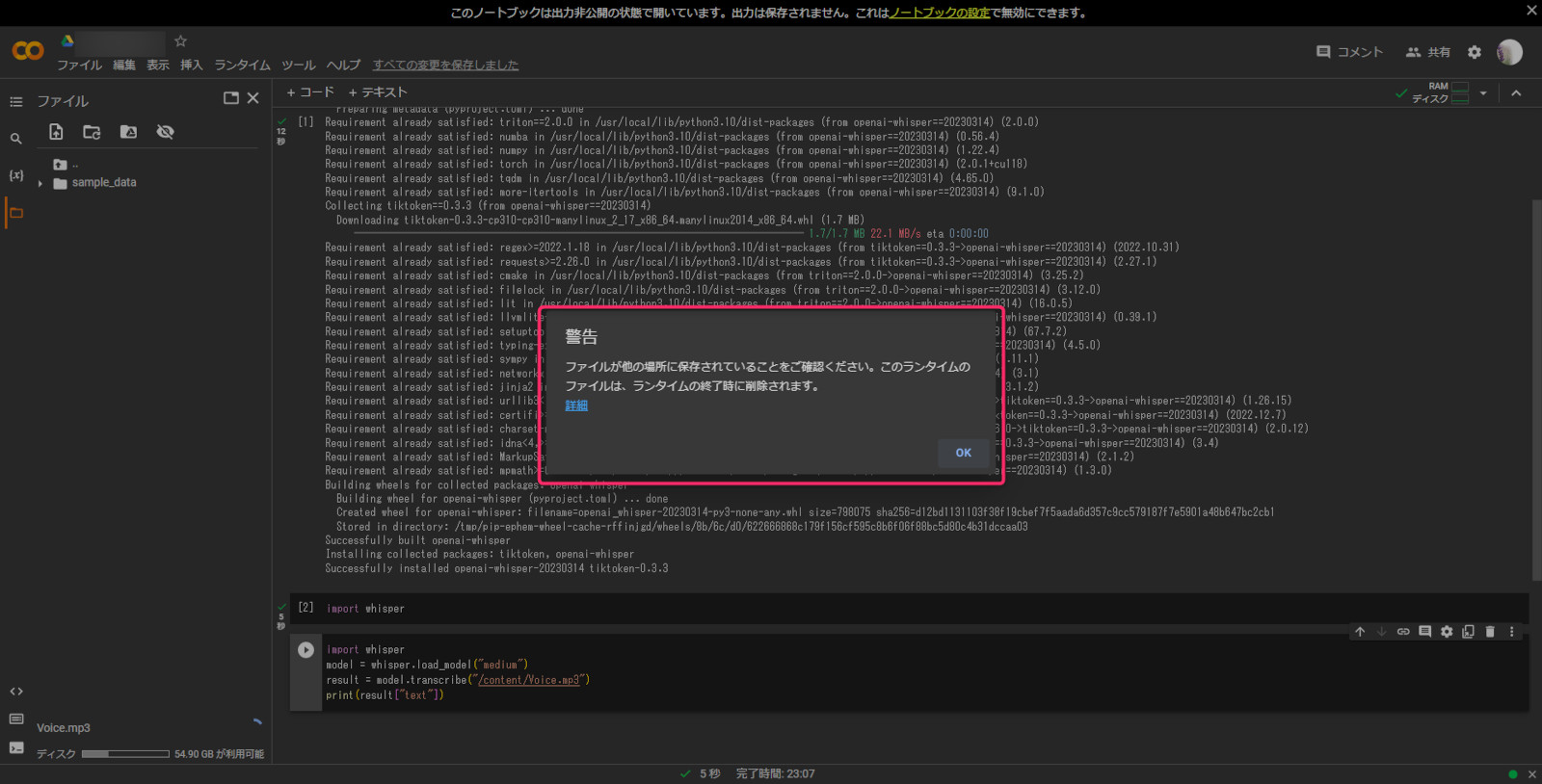
読み込みが始まったら、下記画面になるので、「OK」する。(音声が長い場合は少し時間がかかるので注意)
いよいよ、プログラムで、音声認識する。
下記コードを入力。
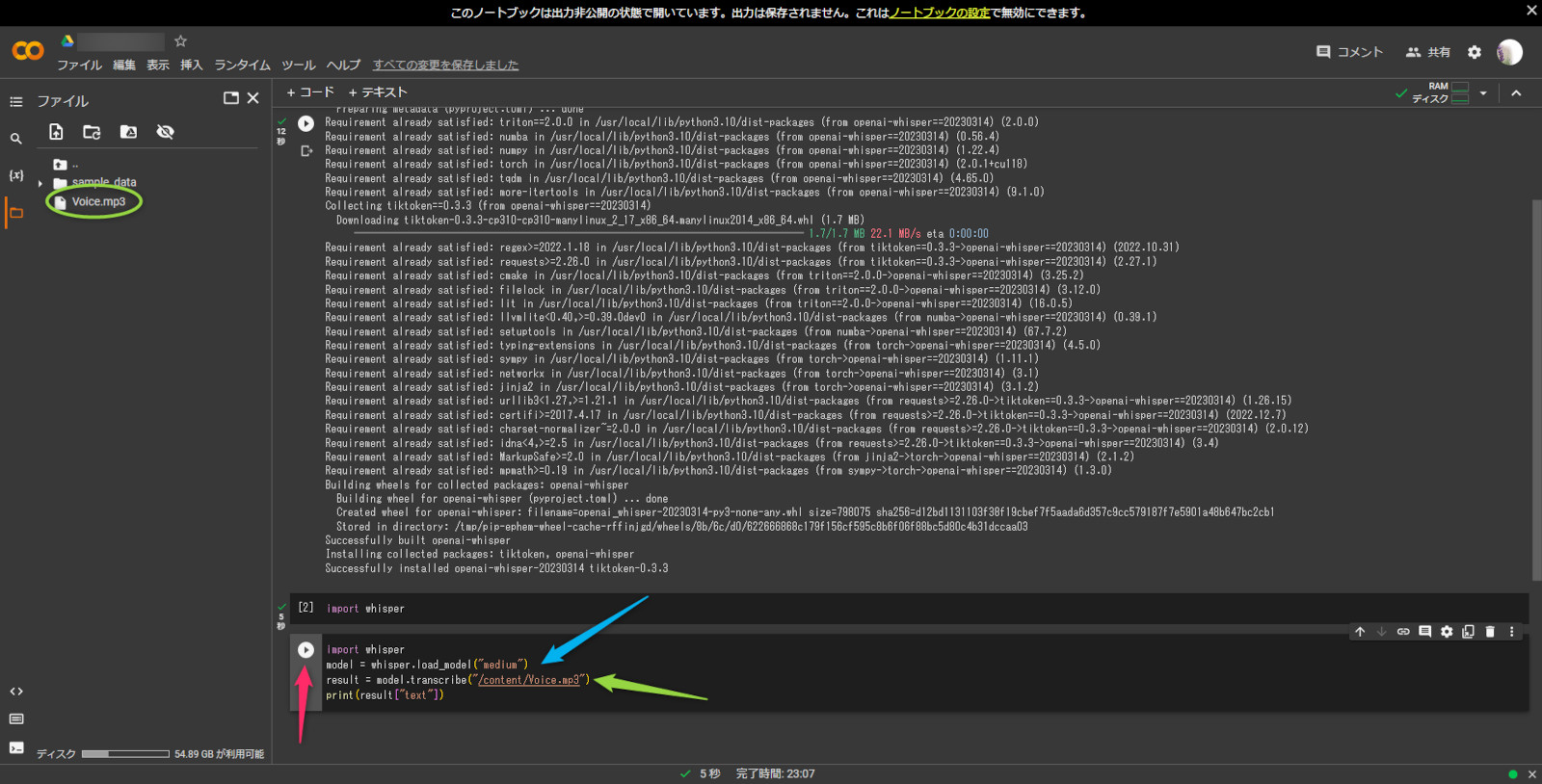
★「ファイル名」となっているところを、先程upした音声ファイル名に置き換える。(画像の緑の矢印の箇所、今回は「Voice.mp3」)
★5つのモデルサイズ「tiny」「base」「small」「medium」「large」が提供されていて一番小さいサイズ「tiny」だと日本語を正しくテキスト化してくれない場合もあるようなので、今回は二番目に大きい「medium」を使いました。下記の2行目の”medium”を他のモデル名に書き換えれば、他のモデルを使えます。(画像の青色の矢印のところ)
import whisper
model = whisper.load_model("medium")
result = model.transcribe("/content/ファイル名")
print(result["text"])ピンクの矢印のところを押して実行。(音声ファイルの読み込みが完了しているか確認してから)
終わると、テキストが書き出されています。(ピンクで囲ったところ)
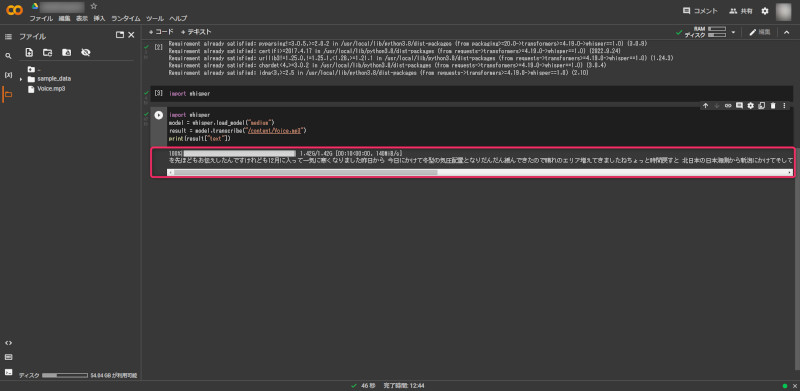
私は、テキストをキーボードのSHIFT+Cでコピーし、テキスト等に貼り付けて、あとの作業は自分のパソコンでします。
★私は「秀丸」というtextソフトを使っているので、それに貼り付けました。今回は、昨日の天気予報の放送を録音したものを音声ファイルとして使いました。句読点は入ったり入らなかったりしますが、ほぼ完璧に聞き取ってくれています。
すごいです。
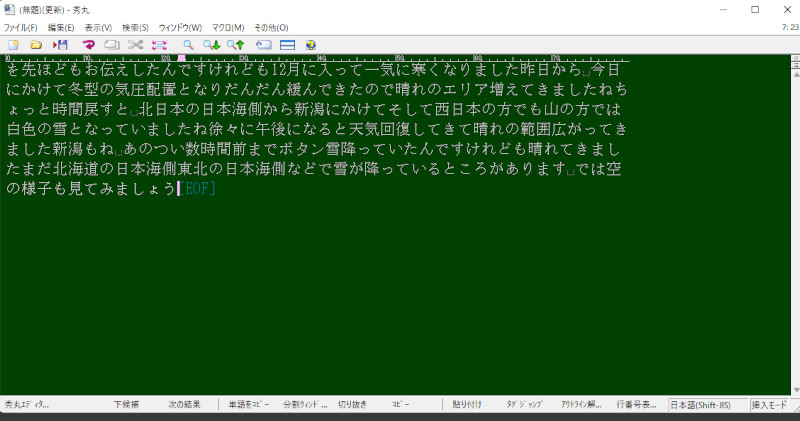
今回はアナウンサーの方お一人のものだったので、ほぼ聞き取ってくれていましたが、たくさんの方が参加するような会議や滑舌の悪い人、録音状態の悪いものは、やはり精度は落ちます。当たり前ですけど。
でも、今まで使ったどれよりも使えます!!
★モデルサイズ「medium」で大体1時間の音声で、実行から10分ぐらいで書き出しが完了します。私は、これで十分です。
★念のため、「Colaboratory」内のデータは削除して残さないようにしています。(意味あるかどうかわかりませんが……)